
tg-me.com/knowledge_accumulator/257
Last Update:
Making Deep Learning Go Brrrr From First Principles
Предлагаю сегодня посмотреть на третий пост от Horace He - разработчика Pytorch - на этот раз по поводу выжимания производительности из говнокода. Мы уже разбирали его пост на тему скорости умножения матриц разного размера, а также о том, почему матрицы из нулей перемножаются быстрее остальных.
В этой статье (2020) проанализировали фактические вычисления и реальные временные затраты в имплементации BERT и получили, что хоть матричные умножения и составляют 99.8% вычислений, на них уходит лишь 61% времени - остальное уходит на element-wise операции / нормализации. Huh?
У любого Deep Learning графа можно выделить 3 вида боттлнеков. Очень полезным будет понимать, какой из боттлнеков является наиболее актуальным в каждом конкретном сетапе. Давайте разберём их по порядку.
Compute - временные затраты на фактическое выполнение вычислений на GPU
В принципе, если в вашей схеме compute - главный боттлнек, то с этим уже можно поздравить - такое бывает нечасто. Но и тут не всё так просто.
В современных GPU есть так называемые Tensor Cores - процессоры, созданные только для умножения матриц. Они выдают в 15 раз больше флопсов, чем обычные ядра, таким образом, все остальные вычисления получают большой штраф к скорости.
Однако, в упомянутом BERT все эти операции выполнялись в сотни раз медленнее, чем матричные умножения, с точки зрения флопсов. И если даже дефолтнейший трансформер упирается в другие боттлнеки, то ваш говнокод явно страдает в основном от них.
Bandwidth - временные затраты на движение данных внутри GPU
Как уже было упомянуто в посте про матрицы, движение данных туда-сюда для вычислений занимает жирный кусок времени выполнения. Чтобы его минимизировать, необходимо фьюзить операции - выполнять много вычислений над куском данных за раз. Есть много уровней болота, на которые можно опуститься. Из элементарного - удалите из своего кода x1 = x.cos() \n x2 = x1.cos() и замените на x2 = x.cos().cos(). Можно фьюзить нормализации с соседними операциями, применять автоматические фьюзеры/компиляторы, ну, а если вы псих, то можно написать свой CUDA kernel на Triton (сам не пробовал).
В посте ссылка на colab, в котором проведён следующий эксперимент - берём тензор размера ~миллион и умножаем на 2 несколько раз с включенным компилятором, который объединяет умножения в один поход в GPU, Что бы вы думали? 16 умножений работают с той же скоростью, что и одно. Лишь после 64 умножений мы начинаем упираться в компьют.
Overhead - все остальные затраты
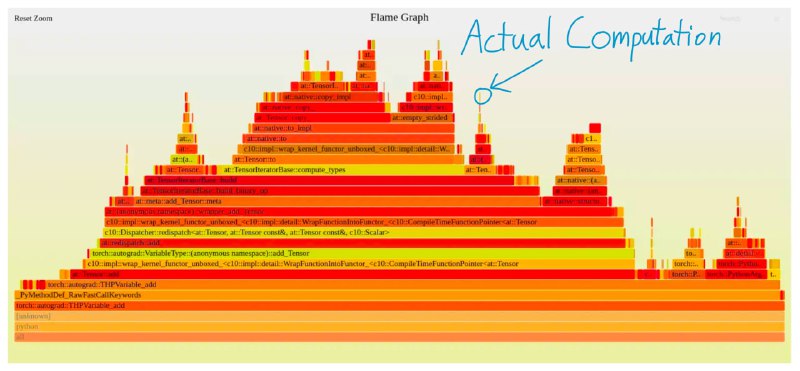
На прикреплённой картинке можно увидеть результат профайлинга пайторча, который производит единичное сложение. Итак, A100 умеет выдавать 312 терафлопсов, чистый питон выдаёт 32 мегафлопсов при сложении, а вот пайторч для вас сделает это лишь 280 тысяч раз.
Пайторч и другие фреймворки не оптимизированы под выполнение маленьких операций, их приоритет - гибкость и комфорт для разработчика, а также скорость выполнения больших операций. Вы можете просто попросить Pytorch посчитать a + b, и под капотом он сделает тонну работы, которая позволяет вам не указывать все типы данных, шейпы и т.д. вручную.
Уменьшать overhead можно тем же методом - используя соответствующий компилятор графа - если это касается самого фреймворка, ну и писать нормальный код, если речь про остальное. Так что, как видите, всё очень просто.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/257